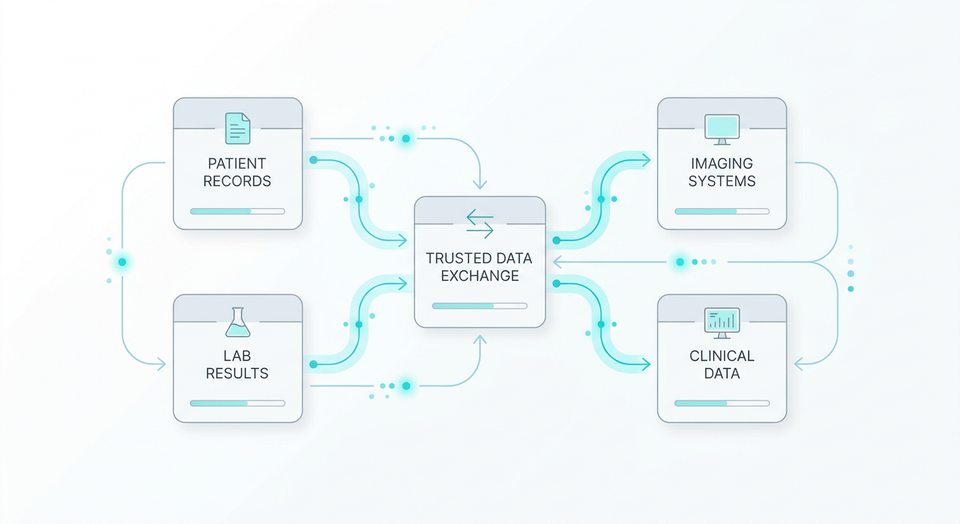
La qualité des données de santé : le coût silencieux de l'information non fiable
La mauvaise qualité des données à l'hôpital dépasse l'informatique : c'est un risque opérationnel. Plongée sur les nouveaux enjeux de la Data Quality en santé : du constat à l'observabilité automatisée avec QALITA.
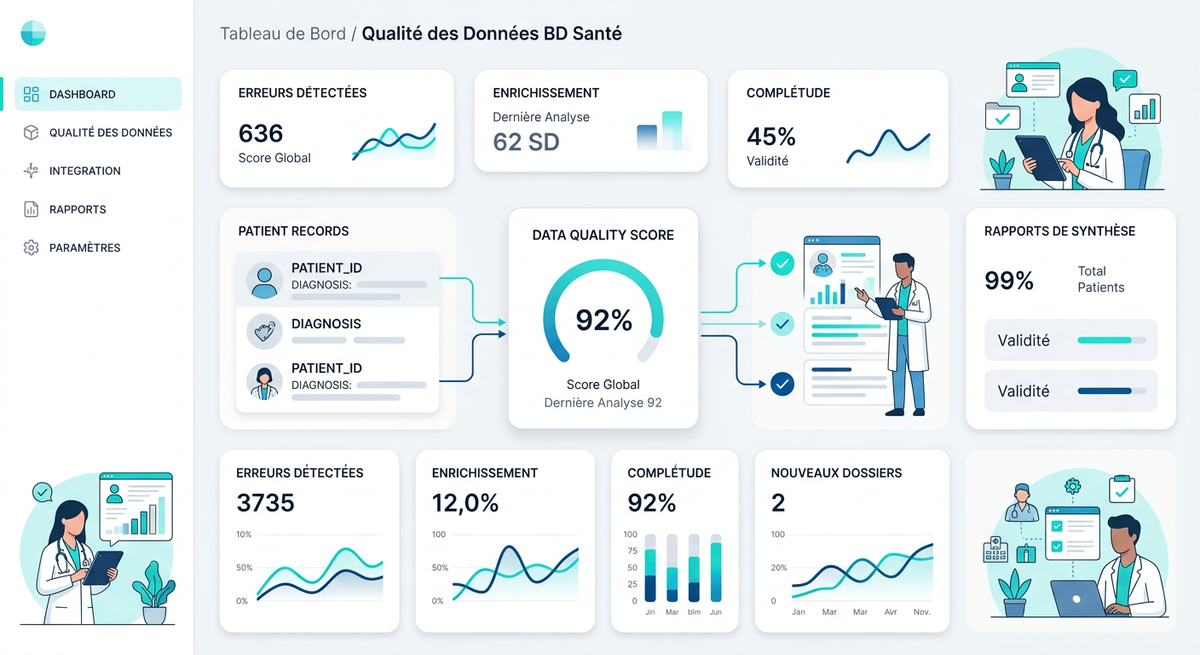
Accroche : La qualité des données, un enjeu vital mais souvent invisible
Dans le secteur hospitalier, chaque donnée enregistrée peut faire la différence entre une prise en charge optimale et une erreur médicale majeure. Les professionnels de santé s'appuient sur des dossiers patients informatisés pour prendre des décisions critiques en temps réel. Pourtant, la gestion de la qualité de ces données reste souvent le parent pauvre des projets de transformation numérique.
Si la puissance des nouveaux agents IA et de l'interopérabilité (via des standards comme FHIR ou SNOMED CT) est une formidable promesse, elle repose sur un prérequis non négociable : la fiabilité à la source. Une IA aussi performante soit-elle "industrialisera vos erreurs" si elle est alimentée par des données fragmentées, obsolètes ou mal structurées.
Constat : Le coût silencieux de la donnée hospitalière non fiable
La mauvaise qualité des données n'est pas qu'un problème informatique, c'est un risque opérationnel majeur. Selon l'Institute of Medicine, les événements indésirables évitables, souvent liés à des erreurs ou omissions dans les dossiers médicaux, figurent parmi les principales causes de mortalité aux États-Unis. En France, l’informatisation massive des processus de soins (DPI, laboratoires, imagerie) a paradoxalement accru la complexité : une information critique comme une allergie sévère peut être correctement saisie dans le logiciel des urgences mais ne jamais remonter dans le dossier partagé.
Les conséquences sont directes :
- Risques pour les patients : Erreurs de diagnostic, traitements inadaptés, ou retards de prise en charge.
- Surcoûts opérationnels : Temps médical perdu à re-saisir ou vérifier l'information, examens redondants.
- Incapacité à innover : Impossibilité de déployer des modèles prédictifs fiables ou des projets de recherche clinique (utilisation secondaire des données) car il faut des mois pour nettoyer les jeux de données bruts.
Décryptage : Pourquoi les approches classiques s'essoufflent ?
Historiquement, l'amélioration de la qualité des données en santé reposait sur des contrôles manuels a posteriori. Des équipes dédiées (DIM, qualiticiens) passent au crible des tableaux de bord ou des extractions Excel pour identifier les incohérences (codes diagnostiques erronés, données manquantes). Cette approche curative montre aujourd'hui ses limites.
D'abord, le volume a explosé. Il est impossible de vérifier manuellement les millions de flux qui transitent chaque jour dans un CHU. Ensuite, l'architecture des SI hospitaliers s'est complexifiée : la donnée vit en silo et est rarement contrôlée lors de son intégration. Un outil de Dataviz montrera les défauts, mais ne pourra pas bloquer une donnée toxique avant qu'elle ne pollue l'entrepôt clinique.
Les DSI hospitalières, face à une injonction de sécurité (HDS, RGPD) et d'innovation (IA, entrepôts de données de santé), doivent repenser la qualité des données non plus comme une correction en fin de chaîne, mais comme une discipline d'ingénierie intégrée dès la source.
Cadre d'action : Passer de la correction manuelle à l'observabilité industrialisée
Pour restaurer la confiance, les hôpitaux doivent passer d’une gouvernance théorique (souvent résumée à un lourd fichier Excel de dictionnaire de données) à une démarche de Data Quality Engineering. Voici le cadre d'action en trois étapes :
- Définir les règles de gestion critiques : Il ne s'agit pas de tout contrôler, mais de cibler les données vitales. Est-ce que l'identifiant national de santé (INS) est bien qualifié ? Est-ce que les codes CIM-10 respectent les formats en vigueur pour le codage de l'activité ?
- Mettre en place des tests automatisés : Comme dans le développement logiciel, les pipelines de données doivent intégrer des tests systématiques (validation de types, complétude, cohérence lexicale).
- Assurer l'observabilité continue : Monitorer la santé des données en temps réel via des tableaux de bord automatisés pour détecter les anomalies (ex: chute soudaine de la remontée d'un flux HL7) avant que l'utilisateur métier ne s'en rende compte.
L'approche QALITA : La qualité des données nativement sécurisée
C'est précisément pour répondre à cette complexité technique et réglementaire que **QALITA Platform** et **QALITA Studio** ont été pensés. Contrairement aux approches curatives, QALITA permet d'industrialiser les contrôles qualité au plus près de la source, en s'intégrant nativement dans les environnements souverains et réglementés de santé.
Notre promesse ? Offrir aux DSI et équipes Data un environnement certifié (HDS, On-Premise) pour définir, automatiser et monitorer les règles de qualité des données sans alourdir la dette technique. QALITA permet de bâtir ce socle de confiance indispensable, que ce soit pour structurer un Entrepôt de Données de Santé (EDS), valider des flux d'interopérabilité, ou préparer le terrain pour un déploiement sécurisé d'agents IA en environnement clinique.
Parce qu'au final, la meilleure IA du monde ne remplacera jamais la justesse de l'information initiale.
Prêt à industrialiser la qualité de vos données de santé et à sécuriser vos futurs projets IA ? Planifiez un échange avec notre équipe pour découvrir comment QALITA peut s'intégrer à votre infrastructure.