Data Quality as Code : automatiser la validation des données dans les pipelines santé
Découvrez comment le Data Quality as Code permet d'automatiser la validation des données dans les pipelines santé et d'industrialiser la confiance dans vos données.

Le pipeline de données ne peut plus être une zone de confiance aveugle
Dans un hôpital ou une clinique, les données circulent en continu : dossiers patients, résultats de laboratoire, prescriptions, imagerie, données de facturation. Chaque flux alimente des décisions cliniques, des tableaux de bord de pilotage, et de plus en plus souvent, des modèles d'IA ou d'analyse prédictive.
Pourtant, une donnée erronée qui passe inaperçue dans un pipeline peut se propager silencieusement à tous les systèmes aval. Une étude de l'Institute of Medicine estime qu'aux États-Unis, les erreurs médicales liées à des données de mauvaise qualité causent chaque année des préjudices évitables représentant des coûts de l'ordre de 10 % des dépenses hospitalières — un ratio que la Cour des comptes juge transposable à la France dans son rapport 2024 sur la qualité des soins. Cour des comptes, 2024
Le constat est clair : la qualité des données ne peut plus être un contrôle ponctuel en fin de chaîne. Elle doit devenir une discipline continue, automatisée et intégrée au pipeline lui-même. C'est ce que l'on appelle le Data Quality as Code.
Data Quality as Code : de quoi parle-t-on ?
Le Data Quality as Code (DQaC) consiste à exprimer les règles de validation des données sous forme de tests exécutables, versionnés dans Git, et déclenchés automatiquement dans des pipelines CI/CD, exactement comme on teste du code applicatif.
Concrètement, au lieu de confier la vérification des données à des audits manuels ou à des scripts ponctuels non tracés, l'équipe data définit des expectations — règles de complétude, d'unicité, de conformité aux formats attendus, de fraîcheur — qui sont exécutées à chaque étape du pipeline. Une violation bloque le déploiement ou alerte l'équipe avant que la donnée n'atteigne les utilisateurs.
Des outils comme dbt tests, Great Expectations, Soda ou le package dbt-expectations permettent d'incarner cette approche dans des environnements de data engineering modernes. Comme le résume l'article de référence de Soda sur les frameworks de qualité des données, cette approche transforme la qualité d'un "exercice ponctuel" en un "processus continu et industrialisé". Soda — Guide Data Quality Frameworks, 2025
Pourquoi le secteur de la santé en a besoin en priorité
Les contraintes des environnements de santé rendent le DQaC particulièrement pertinent :
- Volume et hétérogénéité : les hôpitaux génèrent environ 50 pétaoctets de données par an, selon le Forum Économique Mondial, dont une part importante reste non structurée (comptes rendus cliniques, PDF, fax). WEF — Four ways data is improving healthcare
- Interopérabilité fragile : les données transitent entre des systèmes aux formats variés (FHIR, HL7 v2, CSV, bases propriétaires). Chaque interface est un point de défaillance potentiel.
- Conformité réglementaire : RGPD, HDS, certification HAS — les établissements doivent démontrer la fiabilité de leurs données dans le cadre d'audits. Des tests automatisés tracés constituent une preuve d'audit tangible.
- IA et recherche : les projets d'IA clinique ou de RAG (retrieval-augmented generation) échouent souvent non pas par manque de données, mais par absence de données fiables. Une analyse d'Edenlab souligne que la qualité des données est la condition première pour que les pipelines IA transforment réellement le diagnostic et les soins. Edenlab — AI Data Pipeline Optimization in Healthcare, 2026
Comment mettre en place un framework DQaC dans un pipeline santé
Un framework complet de Data Quality as Code pour la santé s'organise en plusieurs couches :
1. Définir les règles de qualité comme du code
Chaque source, chaque transformation, chaque vue fait l'objet de tests déclaratifs. Exemples concrets pour un environnement hospitalier :
- Vérifier que le champ Numéro Sécurité Sociale respecte le format attendu (validité)
- Contrôler qu'il n'existe pas de doublons patients avec le même identifiant (unicité)
- S'assurer que les codes diagnostics (CIM-10, CCAM) sont valides et référencés (conformité référentielle)
- Vérifier que les données de facturation du jour J sont disponibles avant 8h le lendemain (fraîcheur)
- Détecter les valeurs aberrantes dans les résultats biologiques (plage de vraisemblance)
2. Intégrer les tests dans le pipeline CI/CD
Les tests sont exécutés automatiquement à chaque mise à jour des modèles de données ou des transformations. Si un test critique échoue, le déploiement est bloqué. Un article de Datafold sur la qualité des données dans les workflows data engineering détaille l'importance de cette approche de "quality gate" pour les environnements de production. Datafold — Data Quality in Data Engineering Workflows
3. Surveiller en continu après le déploiement
La qualité des données se dégrade aussi dans le temps : dérive de format, source amont qui change sans prévenir, volume en baisse. Des alertes automatisées permettent de détecter ces anomalies avant qu'elles n'impactent les utilisateurs métier ou les algorithmes.
Un exemple concret : validation des données PMSI
Prenons le cas d'un entrepôt de données hospitalier consolidant les informations du PMSI (Programme de Médicalisation des Systèmes d'Information). Sans DQaC, une erreur de codage dans un GHM (Groupe Homogène de Malades) peut passer inaperçue pendant des semaines et fausser tout le reporting de l'établissement.
Avec DQaC, des tests automatisés vérifient à chaque ingestion que : les codes diagnostics sont bien présents dans la table de référence CIM-10, les âges patients sont cohérents avec les diagnostics, les dates de séjour forment une chronologie valide. Toute anomalie est détectée dans l'heure et remontée à l'équipe data avant d'impacter les indicateurs de l'établissement.
Par où commencer ?
Mettre en place une démarche Data Quality as Code ne nécessite pas de refondre complètement votre infrastructure. Voici une approche progressive :
- Identifier les données critiques : celles qui alimentent des décisions, des tableaux de bord de pilotage ou des systèmes de facturation.
- Définir 3 à 5 règles de qualité par source : commencez simple, avec les contrôles de complétude et de format.
- Automatiser les tests dans votre pipeline existant (Airflow, dbt, Fivetran, Talend).
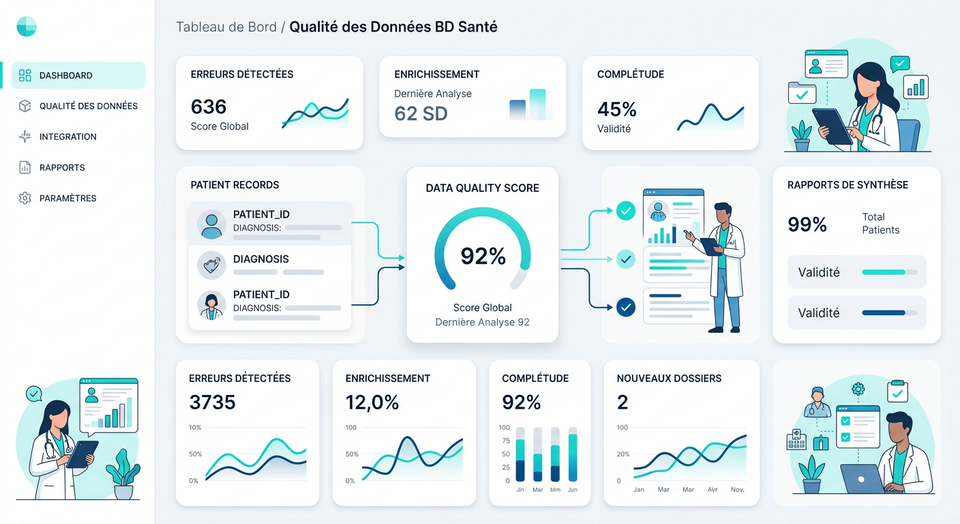
- Ajouter un tableau de bord de suivi pour visualiser l'évolution de la qualité dans le temps.
- Étendre progressivement aux sources secondaires et aux contrôles métier avancés.
Cette méthode permet d'obtenir des résultats visibles en quelques semaines, sans paralyser les équipes data existantes.
La qualité automatisée n'est plus une option
À l'heure où les établissements de santé multiplient les usages de leurs données — reporting, IA, recherche, interopérabilité — compter sur des contrôles manuels intermittents n'est plus tenable. Le Data Quality as Code apporte une réponse industrialisée, traçable et scalable à un problème qui coûte chaque année des centaines de millions d'euros au système de soins.
La bonne nouvelle, c'est que les outils existent, les méthodes sont éprouvées, et les premiers pas sont simples à réaliser.
Vous souhaitez échanger sur la mise en place d'une démarche Data Quality as Code dans votre établissement ou votre DSI ? Réservez un échange avec notre équipe — nous vous montrerons comment QALITA permet d'automatiser la validation de vos données santé en quelques jours, sans refonte de votre infrastructure existante.